零基础入门人工智能 从NLP到GPT的全流程技术体系与实战指南

人工智能(AI)作为当前科技领域最炙手可热的方向之一,正深刻改变着我们的生活与工作方式。对于零基础的初学者而言,掌握人工智能的全流程技术体系是迈向这一领域的关键第一步。本文将系统介绍人工智能的基础知识、核心技术概念以及实战开发要点,带你从入门到精通。
一、人工智能基础概述
人工智能是模拟人类智能的理论、方法、技术及应用系统的一门科学。其核心在于使机器能够执行通常需要人类智能的任务,如学习、推理、感知和语言理解。人工智能的技术体系涵盖机器学习、深度学习、自然语言处理(NLP)、计算机视觉等多个分支。对于初学者,建议从Python编程语言入手,因为它在AI开发中应用广泛,且拥有丰富的库支持,如TensorFlow、PyTorch等。
二、核心技术概念解析
- NLP(自然语言处理):NLP是人工智能的一个重要分支,专注于让计算机理解、解释和生成人类语言。它广泛应用于聊天机器人、语音识别、情感分析和机器翻译等领域。NLP的核心任务包括分词、词性标注、句法分析和语义理解。例如,通过NLP技术,我们可以构建智能客服系统,自动回答用户问题。
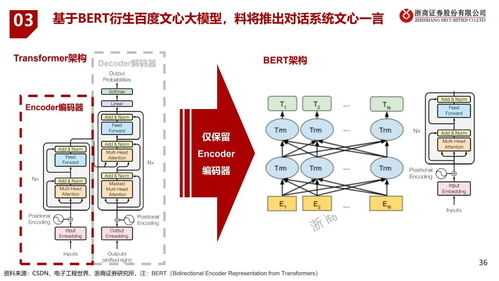
- GPT(生成式预训练模型):GPT是一种基于Transformer架构的预训练语言模型,由OpenAI开发。它通过大规模无监督学习从海量文本数据中学习语言规律,能够生成连贯、有逻辑的文本。GPT的核心优势在于其强大的泛化能力,无需针对特定任务进行大量调整即可应用于多种NLP任务,如文本生成、问答和摘要。GPT的演进版本(如GPT-3、GPT-4)进一步提升了模型的规模和性能,推动了AI在创意写作、代码生成等领域的应用。
- 预训练(Pre-training):预训练是深度学习中的一种技术,指在大规模数据集上训练模型,以学习通用特征或知识,然后再针对特定任务进行微调。这种方法可以显著提高模型性能并减少数据需求。例如,在NLP中,预训练模型如BERT和GPT通过阅读大量文本,学会了语言的语法和语义,从而为下游任务(如情感分类)提供坚实基础。
- 数据标注:数据标注是为原始数据添加标签或注释的过程,是监督学习的关键步骤。在AI项目中,高质量的数据标注直接影响模型的准确性。常见的数据标注类型包括图像分类(如标记图片中的物体)、文本分类(如标注评论的正负面情感)和实体识别(如识别文本中的人名、地名)。对于零基础学习者,了解数据标注的流程和工具(如LabelImg、Prodigy)至关重要,因为它帮助构建训练数据集,是模型开发的基础。
三、人工智能基础软件开发实战指南
要进军人工智能领域,软件开发技能不可或缺。以下是全流程实战步骤:
- 环境搭建:安装Python、Anaconda和常用AI库(如scikit-learn、TensorFlow)。
- 数据准备:学习数据收集、清洗和标注方法,使用Pandas和NumPy进行数据处理。
- 模型构建:从简单模型开始,如线性回归,逐步过渡到深度学习模型。例如,使用TensorFlow或PyTorch构建一个简单的NLP模型,实现文本分类。
- 训练与评估:利用预训练模型(如GPT或BERT)进行微调,使用交叉验证和指标(如准确率、F1分数)评估性能。
- 部署与应用:将模型集成到Web应用或移动端,使用Flask或Django框架,实现实时推理。
实践建议:从开源项目入手,参与Kaggle竞赛,或构建个人项目(如智能聊天机器人)。持续学习最新研究论文和社区资源,如Hugging Face的Transformer库,以跟上AI技术发展。
人工智能领域虽复杂,但通过系统学习NLP、GPT、预训练和数据标注等核心概念,并结合实战开发,零基础者也能逐步掌握全流程技术。记住,实践是通往精通的捷径——开始编码,探索数据,你将发现AI的无限可能。
如若转载,请注明出处:http://www.zmevrel.com/product/17.html
更新时间:2026-06-18 08:29:59